Вики Одинцова : Viki Odintcova as the embodiment of Xochiquetzal -- the real Mexicah archetype of feminine beauty. ('Borgia codex')
Вики Xochiquetzal adorns this cover for a reiser4 enabled Linux kernel 5.3.10-2 build. The build took approximately 30 minutes in an HP ProLiant DL325 Gen10 AMD Epyc 7351P 16-Cores, of which 12 were used, 64GB RAM
The design and implementation of the reiser4 file system
Many users like Linux not for its openness, stability and other important characteristics, but above all for its flexibility. In Linux, there is probably not a single component for which there does not exist an alternative. File systems are no exception.
There are more than two dozen of them. They differ not only in the disk structure and data processing algorithms, but also in the functionality provided. Most of them are so-called third-party file systems implemented for compatibility, such as vfat, ntfs, UFS, etc.. "Native" file systems that provide all the necessary functions for this OS, until recently, there were five: ext2, ext3, reiserfs, XFS, and JFS.
Today you will become acquainted with a novelty in this group -- the reiser4 file system, designed by Hans Reiser and his company NameSys. Despite the name, this file system is written from scratch, although it inherited some features of its “ideological” predecessor – reiserfs.
As well as implementing the traditional Linux filesystem functions, reiser4 provides users with a number of additional features: transparent compression and encryption of files, full data journaling (implemented only in ext3), as well as almost unlimited (with the help of plug-in architecture) extensibility, i.e. the ability to adapt to arbitrarily complex end user requirements. However, there is currently no support for direct IO (work has begun on implementation), quotas, and POSIX ACL.
I hope you have C programming skills and are familiar with the basic principles of organizing modern file systems – without this, it will be difficult to understand the material.
Note: all paths are relative to the fs/reiser4/ directory in the Linux kernel source tree.
Plugins
As mentioned above, reiser4 is based on plug-ins – internal software – separate modules that allow users to adapt the file system to their needs as much as possible.
Only the code which works with the disk, which supports the various abstractions, and balances the tree, is hard-wired into the reiser4 driver, while operations on almost all file system objects – both internal and exported, both disk and in-memory – are implemented as plug-ins and can be expanded with additional types or even replaced. Currently, reiser4 does not support dynamic loading / unloading of plug-ins (i.e., to connect a new module, you will have to recompile the entire driver), but in future versions of the file system, this feature will be implemented.
Strictly speaking, reiser4 is not rigidly defined, neither the disk nor the algorithmic structure, almost any part of it can be easily changed or updated. In this document, I will describe what the developers call “format40” a family of file system properties defined by the standard set of plugins from NameSys.
The details of the plugin infrastructure implementation will be discussed below.
Blocks
The reiser4 partition is a set of fixed-size blocks numbered sequentially starting from zero.
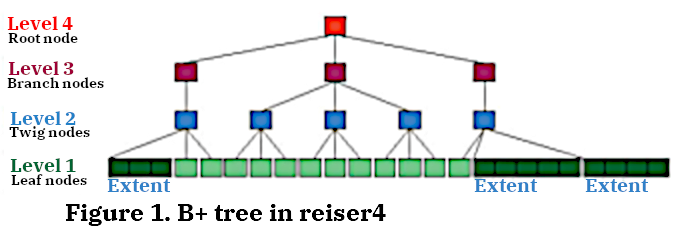
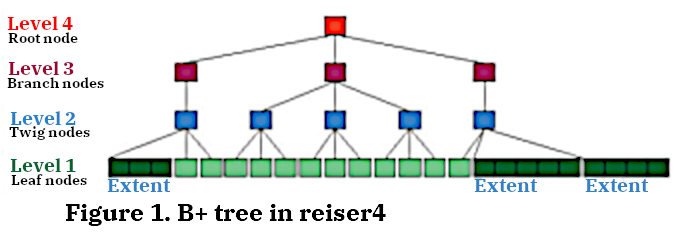
Рисунк 1. В+ дерево reiser4
The maximum number of blocks per partition is 264.The partition starts with 64 kilobytes of unused space left for boot loaders, disk labels, and other required utility.
This is followed by 2 superblocks – the main one and the format one, processed by the disk_format plugin. Behind them is the first bitmap block containing a bitmap of free space. One bit of such a map corresponds to one block of the file system, if the bit is set, the block is busy, if it is reset [cleared], it is free. One bitmap block contains a map for 8 * (BLOCK_SIZE-4) file system blocks. The addresses of the remaining bitmap blocks are calculated using the formula:
bmap_block = 8 * (BLOCK_SIZE-4) * Nwhere N is the ordinal number of the map, i.e. the bitmap is located at the beginning of the area of disk space that it describes. This is done for the convenience of resizefs.reiser4.
Immediately behind the bitmap are the journal header and journal footer blocks used by the reiser4 logging algorithm, and the file system status block containing various parameters of its state completes this sequence.

Reiser4 partition
In memory, any block is represented by a jnode object described in jnode.[ch]. Each jnode has a pointer to a memory page descriptor that contains the data of the corresponding disk block (struct page* pg), a pointer to the data itself (void *data), various locks, reference counters [or link counts], and status bits.Superblocks1
The structure of the main superblock is declared in standard format.h and looks like this:
typedef struct reiser4_master_sb {
char magic[16];
/* Строка : String "ReIsEr4" */
__le16 disk_plugin_id;
/* ID форматного плагина : Format plugin ID */
__le16 blocksize;
/* Размер блока ФС , в настоящее
время может быть равен только размеру страницы (4K на IA32)
* FS block block size, currently
can only be equal to the page size (4K on IA32) */
char uuid[16];
/* Уникальный идентификатор ФС :
FS unique identifier */char label[16];
/* Метка ФС : FS label */
__le64 diskmap;
/* Заготовка на тот случай,
если потребуется изменить положение данных , которые по
умолчанию всегда находятся в определенном месте
*
A blank in case you need to
change the position of the data, which by default is
always in a certain place */
} reiser4_master_sb;
The disk structure of the format superblock is handled by the format40 plugin and is described in the file plugin/disk_format/disk_format40.h :/* Дисковый суперблок для формата 40, 512 байт в длину : Disk superblock for format 40, 512 bytes in length */
typedef struct format40_disk_super_block {/* Количество блоков в ФС : Number of blocks in FS */
d64 block_count;/* Количество свободных блоков : Number of free blocks */
d64 free_blocks;/* Номер коневого блока дерева ФС : Number of the FS tree root block */
d64 root_block;/* Наименьший свободный objectid : Smallest free objectid */
d64 oid;/* Количество файлов в ФС : The number of files in FS */
d64 file_count;/* Сколько раз был сброшен суперблок; пригодится, если в будущем format40 будет иметь несколько суперблоков :
* How many times has a superblock been reset; useful if format40 has multiple superblocks in the future */
d64 flushes;/* Уникальный идентификатор ФС : Unique FS identifier */
d32 mkfs_id;/* Строка : String "ReIsEr40FoRmAt" */
char magic[16];/* Текущая высота дерева ФС : The current FS tree height */
d16 tree_height;d16 formatting_policy;
d64 flags;
char not_used[432];
} format40_disk_super_block;
Status block
The status block format and possible status codes are defined in status_flags.h
struct reiser4_status {
char magic[16];
d64 status;
/* Текущее состояние ФС : FS current state */
d64 extended_status;
/* Некая дополнительная информация о статусе ФС , например номер сектора , на котором произошла
ошибка ввода - вывода – если статус определен как "io error encountered" :
* Some additional information about the FS status, such as the sector number where the I/O error occurred -- if the status is defined as "io error encountered" */d64 stacktrace[10];
/* 10 последних вызовов (адреса) : 10 most recent calls made (addresses) */
char texterror[REISER4_TEXTERROR_LEN];
/* Текст сообщения об ошибке (если есть) или нули : Error message text (if any) or zeros */
};
File system tree
All objects of the file system, with the exception of the superblock and bitmaps, are represented by the leaves of the only balanced external search tree in the entire FS - the B + tree. This organization distinguishes the reiserfs family of file systems from their counterparts (for example, XFS and JFS), which have a more traditional structure that provides a separate tree (or even more than one if indexing by several parameters is required) for each set of objects (for example, inodes tree, extents, and etc.).
The tree consists of internal and leaf nodes. Internal nodes, in accordance with the precepts of the classics, contain keys and pointers to descendants (pointers are always one more than keys), while the leaves, located at the lowest level of the tree, are keys and data organized into items.
Due to the fact that the B+ tree grows up, the first level in the tree is considered leafy. Above it there is a twig level (twig – a thin branch), which is characterized by the fact that only there are extent items (see below), then there are branch levels (branch-a thick branch) and the topmost – the root level. The minimum possible height of the tree is 2, so the root node is always internal. This solution greatly simplified the code, and the loss of disk space was considered insignificant (see Fig. One).
Nodes and leaves of a tree are represented in memory by znode objects (see znode.[ch]), organized in a tree structure. A znode contains a pointer to a jnode containing node data, pointers to the node's parent and its neighbors in the tree, a pointer to a plugin that handles this node type, locks, state bits, and reference counters [or link counts].
The znode abstraction is necessary not only to support an efficient node cache – but also to implement a file system object blocking protocol which improves the performance of tree operations. The importance of this solution can be seen in the example of reiserfs, which does not have a mechanism for blocking tree elements. For synchronization, it uses the fs_generetion counter, which only allows you to establish the fact that the tree has changed. Sometimes this leads to unfortunate consequences: if the thread preparing the balancing does not have time to commit the changes before the tree has been modified by another thread, all the preparation is performed again.
During balancing, the tree is modified one level at a time. During the modification of a certain level, the file system accumulates changes that must be propagated to the next level. For example, inserting an item (a data item having a unique key) sometimes causes items to move between nodes and requires updating the key at least in the shared parent of the modified nodes, and in some cases it may require the placement of a new node, a pointer
towhich must be inserted into the parent node [level]. After all operations at a given tree level have been completed (i.e., an item has been inserted, the nodes repackaged), the process is repeated for cumulative operations at the next level: an existing key is updated or a new key inserted, which can also lead to repacking or placement of a new node. At the same time, new nodes can be blocked and involved, as well as operations can be set up to transfer to the next level.One of the main advantages of multi-level tree balancing is the ability to group changes at the parent level and make them more efficient as a result. Details of the implementation of the balancing code can be found in the carry files.[ch].
Keys
Each separate piece of data or metadata in reiser4 is associated with a key, which is its unique identifier. Keys are used to organize and search data in the FS tree. Based on the fact that the "alloc40" plugin, which is responsible for allocating free space, strives to maintain the tree ordering, one cannot but notice that the key assignment policy directly affects the performance of the file system.
The reiser4 key structure is defined in key.h
union reiser4_key {
__le64 el[KEY_LAST_INDEX];
int pad;
};The key is an array of KEY_LAST_INDEX 64-bit numbers, logically decomposed into fields. A specific field is accessed by two parameters: the index of the element in the key (reiser4_key_field_index) and the offset of the field in the element (reiser4_key_field_shift). See key.h:
/* Значение каждого элемента этого перечисления есть индекс в массиве reiser4_key->el
* The value of each element of this enumeration is an index in the array reiser4_key->el */
typedef enum {/* dirid – ObjectID родительского каталога, расположен в первом элементе , т.н. major "locale" :
* dirid - ObjectID of the parent directory, located in the first element, so-called major "locale"*/
KEY_LOCALITY_INDEX = 0,/* Тип итема , расположен в первом элементе, т.н. minor "locale", :
* The item type is located in the first element, the so-called minor "locale", */
KEY_TYPE_INDEX = 0,/* Существует только в длинных ключах : Exists only in long keys. */
ON_LARGE_KEY(KEY_ORDERING_INDEX,)/* "Объектная связь", второй элемент : "Object Link [relationship]", Second Element */
KEY_BAND_INDEX,/* objectid, второй элемент : objectid, the second element */
KEY_OBJECTID_INDEX = KEY_BAND_INDEX,/* Полный objectid, второй элемент : Full objectid, second element */
KEY_FULLOID_INDEX = KEY_BAND_INDEX,/* Смещение , третий элемент : Offset, third element */
KEY_OFFSET_INDEX,/* Хэш имени , в третьем элементе : Name hash, third element */
KEY_HASH_INDEX = KEY_OFFSET_INDEX,KEY_CACHELINE_END = KEY_OFFSET_INDEX,
KEY_LAST_INDEX
} reiser4_key_field_index;
/* На сколько бит влево должен быть сдвинут элемент ключа для получения значения конкретного поля :
How many bits to the left must the key element be shifted to get the value of a particular field */
typedef enum {KEY_LOCALITY_SHIFT = 4,
KEY_TYPE_SHIFT = 0,
KEY_BAND_SHIFT = 60,
KEY_OBJECTID_SHIFT = 0,
KEY_FULLOID_SHIFT = 0,
KEY_OFFSET_SHIFT = 0,
KEY_ORDERING_SHIFT = 0,
} reiser4_key_field_shift;
From the definition of reiser4_key_field_index, it can be seen that a key in reiser4 can consist of three (short keys) or four (long keys) 64-bit numbers. The key size is determined by the REISER4_LARGE_KEY macro (see reiser4.h). If it is equal to one, an ordering element is added to the enumeration between the type and objectid. The driver can only mount file systems with the key size that was set at compile time. Currently, long keys are used by default.Obviously, the key in reiser4 is more than just an identifier – it contains a lot of additional information about the type and position of the object, which is not duplicated anywhere. Keys are interpreted differently for different types of items. The keys in the internal nodes duplicate the keys of some twig and leaf level items, they are used only when traversing the tree and are not interpreted.
The meaning of the terms "major" (ID of the parent directory) and ”minor" (object type) localities is that in the tree objects are physically grouped first by dirid (this is obtained purely arithmetically, since dirid is located in the most significant bits of the key), and within this group – by type. That is, elements of the same directory and the same type in the tree (and most likely on the disk) will be neighbors.
The current key assignment algorithm implemented by two plugins - "key_large" (long keys) and "key_short" (short keys) – is called "Plan A" (see kassign.[ch]).
Short key
Initially, key_short was the main key assignment algorithm, but later the developers considered insignificant the disk space savings achieved with its implementation. A step was taken in the direction of increased performance with the key_large algorithm.

Directory items - dirid ObjectID of the directory in which the described file is located, + 4 bits type;
- F "fiber" (See plugin/fibration.c);
- H 1, if the last 8 bytes contain a hash;
0, if the last 8 bytes contain the third prefix; - prefix-1 the first 7 characters of a file name;
- prefix-2 the next 8 characters of a file name;
- hash hash of the remaining part of the name, not included in prefix-1 and prefix-2.
File names shorter than 15 characters (7 + 8) are completely placed in the key and are called short. The distinctive feature of such files is the bit H = 0. The names of other files are called long, bit H = 1, the first 7 characters of the name make up the first prefix, and the second 8 bytes make up the hash of the remaining characters. Due to this key structure, the directory elements are sorted approximately in lexicographic order, and the number of collisions (hash matches in different names) is significantly reduced, however, fundamentally unrecoverable with a constant key length.

Stat-data
- locality id ObjectID [object id]2 parent directory, 4 bits per type;
- objectid ObjectID this object.

Extent and tail items
- locality id ObjectID [object id]2 parent directory + type;
- objectid ObjectID this object;
- offset logical offset from the beginning of the file.
Long key
Currently used by default; allows slight performance improvement of tree searches as compared to key_short.

Directory items - dirid ObjectID of the directory in which the described object is located, + 4 bits per type (0 KEY_FILE_NAME_MINOR, directory element);
- F "fiber" (See plugin/fibration.c);
- H 1, if the last 8 bytes contain a hash;
0, if the last 8 bytes contain the third prefix; - prefix-1 the first 7 characters of a file name;
- prefix-2 the next 8 characters of a file name;
- prefix-3 the next 8 characters of a file name;
- hash hash of the remaining part of the filename, not included in prefix-1 and prefix-2.
Short, in this case, are considered names no longer than 23 characters.3
File names shorter than 23 characters (7 + 8+ 8) are completely placed in the key and are called short. The distinctive feature of such files is the bit H = 0. The names of other files are called long, bits H = 1, the first 15 characters of the name constitute the first and second prefixes, and the last 8 bytes make up the hash of the remaining characters. Due to this key structure, [the] directory elements are sorted approximately in lexicographic order, and the number of collisions (hash matches in different names) is significantly reduced, however, fundamentally unrecoverable with a constant key length.3

Stat-data items - locality id ObjectID of the parent directory, + 4 bits type (1 – KEY_SD_MINOR, statdata)
- ordering copy of the second eight bytes of the parent directory key.
{
fibration :7
h :1
prefix-1 :56
}
(See above) - objectid ObjectID of this object
This key structure was introduced to ensure that stat-data items are stored in the directory in the same order as their corresponding directory entries. This improves the performance of the readdir() and stat() calls.

Extent and tail items - locality id ObjectID of the parent directory, + 4 bits of type (4-KEY_BODY_MINOR, file body);
- ordering See above;
- object id See above;
- offset logical offset from the beginning of the file in bytes.
The following types of objects are possible:4
Тип : Type
minor
locality
Элемент каталога : Directory item [entry]
0 stat-data
1 Имя атрибута файла : File attribute name
2 Значание атрибута файла : File attribute value
3 Тело файла : File body
4 The enumeration of object types (minor localities) is defined in key.h:
typedef enum {
/* Имя файла (элемент каталога) : File Name (Directory Element) */
KEY_FILE_NAME_MINOR = 0,/* stat-data */
KEY_SD_MINOR = 1,/* Имя атрибута файла : File attribute name */
KEY_ATTR_NAME_MINOR = 2,/* Значение атрибута файла : File attribute value */
KEY_ATTR_BODY_MINOR = 3,/* Тело файла (tail, ctail или экстент) : File body (tail, ctail or extent) */
KEY_BODY_MINOR = 4,} key_minor_locality;
Nodal blocks
Each disk block containing an internal or leaf tree node begins with a node header consisting of independent and formatted parts. The independent header contains only the ID of the plugin that handles the node of this type (by default, node40 plugin). The format header includes service information which is interpreted by the corresponding plugin (number of items and free bytes, various flags).
See plugin/node/node.h
/* Независимый заголовок узла : Independent node header*/
typedef struct common_node_header {
__le16 plugin_id;/* Идентификатор node- плагина , должен располагаться в самом начале узла :
* The node plugin identifier should be placed at the beginning of the node */
} common_node_header;See plugin/node/node40.h
/* Node header для узлов формата 40. : Node header for format 40 nodes */
typedef struct node40_header {common_node_header common_header;
/* Количество итемов . Должен быть первым элементом в заголовке узла : Number of items . Must be the first element in the node header */
d16 nr_items;/* Свободных байт в узле : Free bytes in a node */
d16 free_space;/* Смещение начала свободного места : Free space start offset */
d16 free_space_start;/* Используются fsck. : Used by fsck. */
d32 magic;
d32 mkfs_id;
d64 flush_id;/* Флаги . Используются fsck и переупаковщиком (repacker) : Flags. Used by fsck and repacker */
d16 flags;/* Уровень узла в дереве. : Node level in the tree */
d8 level;/* Дополнение : Complement */
d8 pad;} PACKED node40_header;
Internal nodes (idef1)
The internal node block of the reiser4 tree consists of a node header, an array of internal items, and an array of item headers, each containing a key, pluginid, and item offset. Both arrays grow towards the middle.

internal node block of the reiser4 tree
/* Дисковый формат internal item : Disk format internal item */
typedef struct internal_item_layout {
reiser4_dblock_nr pointer;
} internal_item_layoutIt can be observed that this is just a pointer to a child node.
Leaves
Leaf nodes are located at the lowest (first) level Of the B+ tree; several different leaf formats are supported,
which areoptimal for certain situations.

Standard leaf node format (leaf1) The list includes a node header, required for all nodes in the tree, an array of item headers, and an array of items themselves (both grow towards the middle). The item header contains the key (the format of which is determined by the assignment policy (long or short keys) and the type of item that the key corresponds to), the pluginid, and a 16-bit offset of the start of the item
'sbody. The item length is calculated as the difference between the offsets of this item and the next. It is not difficult to understand that the length of the zero item located at the end of the node is equal to:len[0] = node_end – offset[0] +1Leaves with variable length of items and keys (lvar)

Variable length leaves of items and keys (lvar)
Leaves with compressed keys (lcomp)

Leaves with compressed keys (lcomp)
Key inherit, a single-byte number, indicates which part of the prefix matches the current and previous keys. Accordingly, in this mode, this part is not repeated to save space. Thus, a kind of key compression is implemented.Items
An item is a separate piece of file system data or metadata that has a unique key associated with it. Reiser4 supports many types of items, their set can easily be expanded by writing additional plugins.
Stat data item
Stat data item contains metadata for files and directories. It is somewhat similar to the inode structure of other file systems, but unlike the classic inode, stat-data does not contain any information about the described object data location on the disk and exports to VFS only the file attributes returned by stat(2) calls.
In reiser4, the structure of each stat-data is composed of several peer-to-peer components called extensions. A special bitmap available in each stat-data indicates the presence or absence of a specific extension. In accordance with the existing code structure, extension handlers are implemented as
REISER4_SD_EXT_PLUGIN_TYPEplugins (see below for plugin types)./* Перечисление возможных расширений stat-data. : Enumeration of the possible extensions of stat-data */
typedef enum {/* Поддержка "легковесных" файлов , атрибуты которых либо наследуются от родительского каталога , либо инициализируются некоторыми разумными значениями :
* Support for "lightweight" file attributes which are either inherited from a parent directory, or are initialized to some reasonable values */
LIGHT_WEIGHT_STAT,/* Данные , требуемые для реализации вызова stat(2). Формат -- reiser4_unix_stat. Если не представлен – файл легковесный. :
* The data required to implement the stat(2) call. Format is -- reiser4_unix_stat. If not provided, the file is lightweight. */
UNIX_STAT,/* Содержит дополнительный набор 32- битных [amc]time полей для реализации наносекундной точности .
Формат – в reiser4_large_time_stat. Использование этого расширения управляется mount- опцией 32bittimes :
* Contains an additional set of 32-bit [amc] time fields to implement nanosecond precision . The format is in
reiser4_large_time_stat. The use of this extension is controlled by the 32bittimes mount option */
LARGE_TIMES_STAT,/* Расширение для символических ссылок : Symbolic Link Extension */
SYMLINK_STAT,/* Если представлено – файл управляется нестандартным плагином ( т.е. плагином , который не может быть вычислен по mode- битам ) :
* If supplied – the file is controlled by custom plugin (i.e. a plugin that cannot be calculated [at the] by mode - bits) */
PLUGIN_STAT,/* Это расширение содержит постоянные (persistent) inode- флаги . Формат в reiser4_flags_stat. :
* This extension contains persistent inode - flags. Format in reiser4_flags_stat. */
FLAGS_STAT,/* Позволяет добавить в stat-data стуктуру capabilities. Сейчас не используется. :
Enables stat-data structure capabilities enhancement. Not currently used. */
CAPABILITIES_STAT,/* Содержит размер и public ID секретного ключа . Формат в reiser4_crypto_stat :
* Contains size and public ID of the private key. Format in reiser4_crypto_stat*/
CRYPTO_STAT,LAST_SD_EXTENSION,
LAST_IMPORTANT_SD_EXTENSION = PLUGIN_STAT,
} sd_ext_bits;
The structures of the corresponding extensions are defined in/plugin/item/static_stat.h.Minimal stat-data (the same extension map) enables support of lightweight files, available in any stat-data:
typedef struct reiser4_stat_data_base {
__le16 extmask;
} PACKED reiser4_stat_data_base;Extension for lightweight files:
typedef struct reiser4_light_weight_stat {
__le16 mode;
__le32 nlink;
__le64 size;
} PACKED reiser4_light_weight_stat;Standard UNIX-stat supporting the full set of attributes returned by the stat(2) call:
typedef struct reiser4_unix_stat {
/* owner id */
__le32 uid;/* group id */
__le32 gid;/* время последнего доступа : last access time */
__le32 atime;/* время последней модификации : last modification time */
__le32 mtime;/* время последнего изменения : last change time */
__le32 ctime;union {
/* пара [minor,major] для файлов устройств : [minor, major] pair for device files */
__le64 rdev;/* размер в байтах для регулярных файлов : size, in bytes, for regular files */
__le64 bytes;} u;
} PACKED reiser4_unix_stat;
Symbolic links extension containing the name pointed to by a symlink:typedef struct reiser4_symlink_stat {
char body[0];
} PACKED reiser4_symlink_stat;In this extension the plugin stores some parameters about its state:5
The container for storing the plugin state parameters is not an independent extension and is included inreiser4_plugin_stat:typedef struct reiser4_plugin_slot {
__le16 pset_memb;
__le16 id;
} PACKED reiser4_plugin_slot;Extension for files with non-standard plugins is used to store required number of plug-ins state parameters:
typedef struct reiser4_plugin_stat {
__le16 plugins_no;/* Количество дополнительных плагинов , ассоциированных с объектом :
* number of additional plugins , associated with the [an] object */
reiser4_plugin_slot slot[0];
} PACKED reiser4_plugin_stat;Extension for inode flags. Currently, this is just a 32-bit mask, which can be replaced with a variable-length mask if necessary:
typedef struct reiser4_flags_stat {
__le32 flags;
} PACKED reiser4_flags_stat;Extension capabilities (not currently used):
typedef struct reiser4_capabilities_stat {
__le32 effective;
__le32 permitted;
} PACKED reiser4_capabilities_stat;An extension for storing logical cluster size (cryptcompress objects attribute). In fact, it is not the size itself that is stored, but its binary logarithm, so the size is found as
cluster_size = 1 << cluster_shift.typedef struct reiser4_cluster_stat {
d8 cluster_shift;
} PACKED reiser4_cluster_stat;Extension for encrypted objects attributes:
typedef struct reiser4_crypto_stat {
d16 keysize;/* размер секретного ключа в битах : private key size in bits */
d8 keyid[0];/* ID секретного ключа : private key ID */
} PACKED reiser4_crypto_stat;Exact time extension:
typedef struct reiser4_large_times_stat {
d32 atime;
d32 mtime;
d32 ctime;
} PACKED reiser4_large_times_stat;Extension for the single directory entry plugin (not currently used):
typedef struct sd_stat {
int dirs;
int files;
int others;
} sd_stat;Tail item
Tail items contain raw file data (either whole small files or "tails" of large files) and have no format structure.
Extent items
Extents, in terms of reiser4 – are continuous sections of disk space whose descriptors, which make up the item extent, contain the number of the starting block of the section and its length. The extent structure is defined in
plugin/item/extent.h:typedef struct {
reiser4_dblock_nr start;
reiser4_dblock_nr width;
} reiser4_extent;In reiser4, extents are used to track only allocated disk space (unlike other file systems, where arrays or trees of free-space descriptors replace block-occupancy bitmaps) and refer to sections containing file data. In extent keys that belong to a single file, all fields are equal, except for the offset (offset of the "chunk" described by this extent from the beginning of the file).
The extent can be in one of the following states (plugin/item/extent.h):
typedef enum {
HOLE_EXTENT,
UNALLOCATED_EXTENT,
ALLOCATED_EXTENT
} extent_state;where:
HOLE_EXTENT:
The extent is a " hole” in the file. The “hole” can be formed, for example, after the call:
creat();6
truncate(4096);
As a result, a 4 KB file will be filled with uninitialized data, which is pointless to allocate disk space for (although XFS, for example, not only allocates, but also overwrites it with zeros). When trying to read hole-extent data, the file system will dynamically "generate" the required number of null [zero] bytes and pass them to the user. The descriptor of such an extent contains only its length and does not point anywhere.UNALLOCATED_EXTENT:
A "virtual" extent that is the result of a deferred allocation policy. It appears as a result of adding data to a file or when filling in "holes". It exists only in memory and upon being reset, having received a real disk address from the flush algorithm, it turns into a normal extent.ALLOCATED_EXTENT:
ordinary extent.
ctail item
In addition to the classic implementation of regular files (unix-file plugin), reiser4 offers another in which the file data is stored on disk in a compressed and (or) encrypted form (transparent compression/encryption). The cryptcompress plugin is responsible for this implementation. Its main idea is to perform compression and encryption immediately before flushing cached data to disk, while saving CPU resources in the case when the same data in memory is repeatedly modified by one or more processes. On modern machines equipped with fast processors and large amounts of RAM, data compression does not degrade, but on the contrary – increases the performance of the file system, because data conversion is performed relatively quickly, and the volume of disk traffic is reduced.
Each data transformation or conversion (compression, encryption, etc.) is performed by some algorithm that is present in reiser4 in the form of a corresponding plugin (the so-called transform plugin). It is worth noting the benefits of plug-in architecture, in which support for any desired compression or encryption algorithm is reduced to just writing and adding a standard plug-in of the appropriate type. Currently, transform-plugins are available for compression by the gzip1, lzo1, and Zstd (added on 2017-11-26) algorithms, in principle, you can encrypt using any block algorithm supported by the Linux kernel crypto-API, as well as aes_ecb, but support for crypto plug-ins has not yet been brought to mind.
The cryptocompress plugin splits each file into logical clusters of a certain size. This size is an attribute of this file and must be assigned before it is created. Each logical cluster is mapped in memory to the corresponding page cluster, which, in turn, is represented in a balanced tree by a so-called disk cluster. Compressed data of such a file is stored on the disk in the form of "fragments", implemented in reiser4 as items of a special type (actually ctail-items), which greatly simplifies random access to data. Each logical cluster is compressed independently of the others. Of course, clusters should not be too large, so as not to take up too much memory when trying to read or write anything at an arbitrary offset: the maximum size of the logical cluster supported by reiser4 is 64K. This circumstance somewhat reduces the degree of data compression due to the inability to create an extensive dictionary in the compression process.
A logical cluster of index I is a set of bytes of a given file whose offsets lie in the segment
[I * S, (I + 1) * S — 1], where S is the size of the logical cluster. Currently, Reiser4 supports clusters with sizes 4K, 8K, 16K, 32K and 64K, but not less than PAGE_SIZE). A logical cluster is called a partial cluster if it contains less than S bytes.An index I page cluster is a sequence of pages containing raw (uncompressed and unencrypted) data from the corresponding logical cluster. The page cluster is present in memory while reading or writing a file.
A disk cluster of index I is a sequential set of items of some type, the first of which has a key with an offset that is calculated as a function of I (this is managed by a special method of the item plugin). The size of the disk cluster is defined as S * N, where N is the coefficient of expansion of the crypto-algorithm that encrypts the file (N = 1 for all symmetric algorithms).
Currently, only ctail-items which structure is defined in plugin/item/ctail.h are "clustered":
typedef struct ctail_item_format {
d8 cluster_shift;/* Двоичный логарифм размера дискового кластера : Binary logarithm of a disk cluster size */
d8 body[0];/* Тело итема : The body of an item */
} __attribute__ ((packed)) ctail_item_format;Each disk cluster is a compressed and encrypted data of a logical cluster, divided into ctail-items, in a specific format, which is not represented by any data structure and has the following form:
data {add control_byte check_sum}The addition is used to align the compressed data before encryption, so that the final size is a multiple of the size of the cryptographic algorithm block. The control byte stores the size of the complement, increased by 1 (in fact, this is the size of the section that will need to be cut off before decompression). The check sum is the adler32 from the aligned and encrypted data.
The check sum insulates us from attempting decompression on incorrect data (the latter case is fraught with fatal consequences, since it is allowed to use unsafe compression algorithms (which, as a rule, are the fastest). The checksum is added only if the compression has succeeded (in this case, the total size of the data, taking into account the check sum, must be strictly less than the size of the disk cluster). If the data of the logical cluster is poorly compressed, the outcome of the compression is rejected and no checksum is added to the aligned and encrypted logical cluster. With this approach, adjacent disk clusters do not "overlap" on each other by offsets in their keys. Another important advantage is that for each disk cluster, you can immediately determine whether compression was performed or not.
When reading a file by any offset, page clusters of corresponding indexes are placed in memory. When a request is made to read a page, the file system places the entire page cluster in memory (the key is constructed according to the offset, all the ctail items of the corresponding disk cluster are sequentially located and compiled, after which the pages are decrypted, decompressed, and filled with raw data). At the same time, trying to read a little more than is necessary (the virtual memory Manager does not know anything about clusters) does not cause damage and fits into the General concept of read-ahead or pre-emptive reading.
You can read more about this plugin in [4].
Compound directory item
A compound directory item consists (in contrast to a single directory item, which is currently not used and thus will not be described here) of multiple directory items. It was introduced in order to increase the efficiency of disk space usage. The fact is that all elements of the same directory have the same fragment in their keys – the ObjectID of the parent directory. The layout of a compound item from several elements of the same directory enables the storage of the specified key fragment only once and thus save a little disk space. This solution is a special form of key compression, since their full compression is not implemented in version 4.0. Note also that the keys are stored unaligned on disk, which, at least on some architectures, increases the CPU load when processing them, but again saves space.
The disk structure of the compound directory element (CDE) item is as follows:

disk structure of the compound directory element (CDE) item
The formats of its components are defined in plugin/item/cde.h:7typedef struct cde_unit_header {
de_id hash;
/* Часть ключа (2 последних элемента) : Part of the key (last 2 elements) */
d16 offset;
/* Смещения тела элемента каталога : Body of elements directory offset */
} cde_unit_header;
typedef struct cde_item_format {
d16 num_of_entries;
/* Количество элементов каталоге : Number of elements in the directory */
cde_unit_header entry[0];
/* Массив заголовков элементов : Array of header elements */
} cde_item_format;
typedef struct directory_entry_format {
/* Формат элемента каталога (directory entry) : Directory element (directory entry) format */
obj_key_id id;
/* Ключ stat-data итема описываемого объекта . Нет нужды хранить его целиком , т. к. это всегда ключ stat-data и, ледовательно , тип и offset могут быть опущены . Однако из - за возможности применения других схем назначения ключей здесь зарезервировано место для целого ключа :
* The described object stat-data item Key. There is no need to store it in its entirety, since it is always the stat-data key and therefore the type and offset can be omitted . However, due to the possibility of using other key assignment schemes, space is reserved here for the whole key */d8 name[0];
/* Имя объекта – строка с NULL- байтом в конце : Object name is a string with a NULL byte at the end */
} directory_entry_format;
The CDE item header contains the number of items in the directory. The header of a directory item includes part of the key of the object described by the item (hash of the name) and the offset of the body of the item itself in the item. The directory element consists of the stat-data key of the item being described (in fact, there is no need to store the entire key - since it is always stat-data, the type and offset can be omitted. However, due to the possibility of using other key assignment schemes, space is reserved for the whole key) and the object name.Insights
Summarizing the above material, we can say that a regular file/directory in reiser4 consists of objects of three types:
- Directory element -- or entry contains the object name and the stat-data item key;
- stat-data item – attributes;
- one or more items containing the object body – for a regular file, these are extent/tail/ctail items, for a directory these are CDE items; special files (devices, FIFO, etc.) lack bodies.
All items belonging to a given file have the same dirid and objectid in their keys.
Journaling
Reiser4 supports full journaling of data and metadata, while also providing some advanced features.
The fact is that most file systems perform write caching - modified data is not immediately flushed to disk, but accumulated in the cache. This enables the FS not only to better control disk scheduling, but also to generate long I/O requests, which are processed by modern hard disks much faster than a group of short ones. In the event of a system failure, not only will recent changes be lost – but the caching mechanism can reverse write requests, resulting in newer data being written and older data being lost. This can be a serious problem for applications that make multiple dependent modifications, some of which will be lost while others will not. Such applications require the FS to ensure that either all or none of the changes will survive the failure.
Dependent modifications can also occur when an application reads the modified data and then produces output such as:
- Process 1 writes to file A.
- Process 2 reads from file A.
- Process 2 writes to file B.
Obviously, file B may depend on file A, and if the caching strategy changes the order in which changes are committed to these files, applications may be in an incorrect state after a crash.
Aтом – a set of blocks which modifications must be atomically written to disk. Every change to the FS object that is not fixed on the disk is an atom. For example, if an application adds data to the end of a file, the atom will include a block containing the new data itself, a block with a stat-data item containing the length of the file, and a block storing the tail/ctail/extent item. If a new block is placed – a superblock storing the free space counter and a bitmap block will also be added to the atom (in fact, the journaling algorithm for the superblock and bitmaps is somewhat more complex, see below).
Transcrash – a set of operations which, all or none, will survive a system failure.
There are 2 types of transcrashes: read-write and write-only. If an application writes to a modified block which has not yet been committed to disk, the atoms embodying these two modifications are combined into a write-only transcrash. If the application reads the data from an uncommitted block and then writes – these 2 atoms merge into a read-write transcrash.
For more information about the mechanism implementation described above, see the comments in the txnmgr files.[ch], as well as in [3].
Low-level journaling mechanisms are implemented in wander.[ch] and are also quite unusual. To begin with, reiser4 does not have a journal (allocated disk area) in the usual sense. "Wandering" journal blocks are placed randomly, anywhere in the file system. And instead of writing the journal block twice (once to a "wandering" location, the second to a real one), reiser4 can write the block to a new location and then update the pointer in its parent. It would seem that there is no difference – after all, the modification of the parent will still have to be included in the transaction, notwithstanding, when journaling at least three blocks with a common parent, the benefit becomes obvious. The traditional solution is called block rewriting, and the described solution is called relocation.
The decision to relocate or rewrite is made for performance reasons. By writing journaled blocks to new locations, the FS avoids having to make a copy of each block in the journal. However, if the initial position of the relocated block is optimal, a change in its coordinates may increase fragmentation.
From now on, by an atom commit, we understand it as the journaling of its constituent blocks in wandering positions, and by a flush we mean the writing of blocks at real coordinates. It is clear that for a relocated set of atoms, these two stages coincide.8
A rewritable atom set contains all dirty blocks that do not belong to a relocatable group (i.e. blocks that do not have a dirty parent, for which rewriting would be the best way out). A "wandering" copy of each block is written as part of the journal before the atom is fixed, and replaces the original block content after it is fixed. Note that the superblock is considered the parent of the root node, and bitmap blocks have no parents. Therefore, they will always be processed as part of a rewritable set (there is also an alternative definition of a minimum rewritable set, which is similar to the standard one except for the following conditions: if at least 3 dirty blocks have a common clean parent, then their parent is added to this minimum set, and the blocks themselves are moved to the relocate group. This optimization will be retained for future versions).
Depending on the system and workload, you can choose one of three journaling policies:
- Always Relocate – this policy includes a block in the relocated set in any case, reducing the number of blocks flushed to disk (optimizes write).
- Never Relocate – This policy disables relocation. Blocks are always written to the original location with journaling via rewriting, the tree does not change (optimizes reading).
- Left neighbor – this policy moves the block to the closest possible location to its left neighbor (in tree order). If this position is occupied by some block of the running atom, the policy makes the block a member of the rewritable set.
Metadata journaling
This is a limited mode of operation of the journaling mechanism, in which only file system metadata is protected by an atomic record. In this mode, file data blocks (unformatted nodes) are not affected by the journaling mechanism and therefore do not need to be flushed to disk as a result of a transaction commit. In this case, the file data blocks are not considered members of the relocate or overwrite sets, because they do not participate in the atomic update protocol, and the only reasons for resetting them to disk are memory overflow and age.
Bitmap blocks processing
Reiser4 places temporary blocks for "wandering" journaling. This means that there are differences between the content of a fixed or committed bitmap block that needs to be restored after a failure, and the content of a working bitmap block that is used to find/allocate free blocks.
For each bitmap-block, 2 versions are stored in memory: WORKING_BITMAP and COMMIT_BITMAP
The working bitmap is used simply to search for free blocks. if a certain bit is allocated in the working map, the corresponding block can be allocated. The working map is updated every time a block is allocated. The Commit map reflects changes made to already committed atoms or to an atom that is currently being executed (atoms are fixed sequentially, and only one can work at any given time). The Commit map is updated only when the atom is committed, i.e. the state of the blocks allocated to the journal during the atom processing is never reflected in it.
Having two bitmaps in memory is very efficient as that enables multiple atoms to modify a single bitmap block.
Another critical resource in reiser4 is a superblock containing a free block counter. A similar technique is applied to it, allowing many atoms to modify this counter. (See below)
Wandering journaling
The reiser4 journaling algorithm allocates and writes wandering blocks and supports additional atomic disk structures like wander-records (each takes 1 block) containing general information about the transaction and wandering blocks table mapping(s) to their real coordinates.
Transaction disk structure as follows:

Reiser4 journaling
Below you can see how the corresponding data structures are defined in reiser4.struct tx_header {
char magic[TX_HEADER_MAGIC_SIZE];
/* Магическая строка делает первый блок в транзакции отличным от других журналируемых блоков, это должно помочь fsck :
* Magic string makes the first block in a transaction different from other logged blocks, it should help fsck */d64 id;
/* ID транзакции : Transaction ID */ d32 total;
/* Общее количество wander- записей ( включая эту , tx head) :
* total number of wander records (including this one, tx head) */d32 padding;
/* Выравнивает предыдущее поле по 8- байтной границе , всегда 0 :
* Previous field aligns on 8- byte boundary, is always 0 */d64 prev_tx;
/* Указатель на заголовок предыдущей транзакции : Pointer to the header of the previous transaction */
d64 next_block;
/* Положение следующей wander- записи : Location of the next wander record */
d64 free_blocks;
/* Зафиксированная версия счетчика свободных блоков : committed versions of free blocks counter */
d64 nr_files;
/* Количество файлов и следующий свободный ObjectID журналируются отдельно от суперблока :
* number of files and the next available ObjectID logged separately from superblock */d64 next_oid;
};
struct wander_record_header {
char magic[WANDER_RECORD_MAGIC_SIZE];
/* Если не известно положение wander- записей, эта строка поможет fsck найти их. :
* If the position of the wander records is not known, this line will help fsck find them */d64 id;
/* ID транзакции : Transaction ID */
d32 total;
/* Общее количество wander- записей в транзакции : total number of wander records in the transaction */
d32 serial;
/* Количество блоков в транзакции : number of blocks in a transaction */
d64 next_block;
/* number of next block in commit */
};
struct wander_entry {
/* Остаток блока, содержащего wander запись, заполняется этими элементами, а неиспользованное место – нуями :
* remainder of the block containing the wander record is filled with these elements, and the unused space is filled with zeros */d64 original;
/* Оригинальное положение блока : original position of the block */
d64 wandered;
/* Странствующее положение блока : wandering position of the block */
};
To manage the journal in reiser4, there are 2 blocks that have a fixed position on the disk: the journal header (contains a pointer to the last committed transaction) and the journal footer (contains a pointer to the last dropped or reset transaction). An atomic journal header record indicates that the transaction has been committed (i.e., will survive a failure), and a journal footer record indicates that all postfix records have been completed (i.e., the transaction is thoroughly complete, all blocks are written in their places). After a successful footer record, all wander blocks and wander entries are released. See wander.h:struct journal_header {
/* Формат блока заголовка журнала : journal header block format */
d64 last_committed_tx;
/* Положение заголовка последней зафиксированной транзакции : Last committed transaction header position */
};
struct journal_footer {
/* Формат journal footer блока : journal footer block format */
d64 last_flushed_tx;
/* Положение последней сброшенной транзакции . Этот указатель не является истинным после того , как транзакция , на которую он указывает , сброшена , а используется только в процессе восстановления для определения конца дискового списка зафиксированных транзакций , которые не были успешно сброшены. :
* The position of the last flushed transaction. This pointer is not true after the transaction it points to is flushed, but is only used in the recovery process to determine the disk list end of committed transactions which were not successfully flushed. */d64 free_blocks;
/* Счетчик свобоных блоков во время сброса транзакции записывается в journal footer, а не в суперблок, т. к. он журналируется отлично от других полей суперблока (например , указателя на корень дерева) :
* The free blocks counter during a transaction flush is written to the journal footer, and not to the superblock, i.e, it is logged differently from other superblock fields (for example , a pointer to the root of a tree) */d64 nr_files;
/* Количество файлов и максимальный OID также журналируются отдельно от суперблока :
number of files and maximum OID also logged separately from superblock */d64 next_oid;
};
In the header of each transaction and in the journal footer block there is space for logging the superblock fields containing the free blocks counter, the number of files in the file system, and the minimum available ObjectID.The process of committing an atom includes several stages:
- Size of the rewritable atom set is calculated.
- Required number of wander records is calculated, and the necessary blocks are allocated for them.
- Wandering blocks are allocated and wander records are filled in.
- Wandering blocks and wander records are sent to be logged.
- I/O completion is expected.
- The journal header is updated: the last_commited_tx pointer is set to current transaction tx_header block, the modified journal header block is sent for writing, and I/o completion is expected.
Atom flush:
- Rewritable atom set is written in the original coordinates.
- I/O completion is expected.
- The journal footer is updated: the last_flushed_tx pointer is set to the tx_header block of the current atom. Footer-block is sent for recording.
- I/O completion is expected.
- Disk space allocated to wandering blocks and wander records is freed up (changes are made to working bitmaps, nothing is written to the disk)
It is easy to understand that when the recovery procedure searches for incomplete transactions, it compares the values of the last_commited_tx (journal header) and last_flushed_tx (journal footer) fields, and if they are not equal, it starts moving through the circular list of wander records, flushing all transactions that the file system managed to commit before the failure.
You can read more about the mechanisms described above in the wander file commentaries.[ch] and in [3].
Plug-in infrastructure
All reiser4 plugins are classified into several types. Same type plugins are called instances of it. The label in the form of a pair (type_label, plugin_label) is unique and globally stable, plugin identifiers visible to the user. Arrays are supported inside the kernel, in which these numbers are indexes. Static dictionaries are also supported, which are mappings of plugin labels to internal identifiers of type reiser4_plugin_type stored in file system objects.
Plugin labels have a value for the user interface that assigns plugins to objects, and will be used for dynamic loading in the future. The reiser4_plugin_type ID is an index in the internal static plugins array[].
The file system object that corresponds to a plug-in of a certain type is named, without further ado, as a subject of this type and its specific instance. With each subject, the plugin can store some state (for this purpose, there is a special extension reiser4_plugin_slot in stat-data). For example, the state of a Director plugin (which is an instance of an object type) is a pointer to a hash plugin.
In addition to the numeric identifier, each type and instance has a text label (short string) and a definition (long string), hard-coded in the plugins [] array. The plugin can also be reliably identified using this pair.
A whole set of plugins is associated with each inode (open file). Storing pointers to them in every inode is an unforgivable memory loss. Instead, reiser4 supports multiple global data structures of the struct plugin_set type, each of which stores a set of plugins for a specific type of object. Inode contains only a pointer to its plugin_set type.
Data structures used by the plug-in infrastructure, as well as the possible types and implemented instances are described in the files:
- plugin/plugin.[ch]
- plugin/plugin_header.h
- plugin/plugin_set.[ch]
Conclusion
I would like to note that during the year of operation on my workstation, reiser4 proved to be a fairly stable and fast file system. For anyone who has time, I recommend that you try it at least on your home machine, where the damage from possible data loss is not so great (although I myself have not had any problems with reiser4 for a long time, bug reports are still received quite often in the developers ' mailing list).
In vanilla-core, the reiser4 driver is not yet enabled, and is only permanently available in the-mm branch of Andrew Morton: www.kernel.org/pub/linux/kernel/people/akpm/patches/2.6.
On the ftp site developers (
ftp://namesys.com/pub/reiser4-for-2.6) can also be found informal reiser4 patches for some vanilla-cores, however, they come with some delay and are practically unsupported.Sources:
- Source for the reiser4 file system driver.
- Hans Reiser "Reiser4 whitepaper" –
www.namesys.com/v4.html. - Joshua MacDonald, Hans Reiser, Alex Zarochentcev, "Reiser4 transaction design document" –
www.namesys.com/txn-doc.html. - Edward Shishkin, "Reiser4 cryptcompress regular files" –
www.namesys.com/cryptcompress_design.html. reiser4.wiki.kernel.org
The latest version of this document, as well as similar topics of articles and translations can be found at
www.filesystems.nm.ruNotes:
Best effort compilation from two works on reiser4 I found online. Issue is that those sources are in Russian and I struggled with their translation into English.Translation Resources:
- RussianDict translate Луна: Metztli
- Yandex translate информационная : Information
- Google translate технологии : Technology
Probably there exist better translations of these sources somewhere online but I was unable to find any.
Originally found PDF by Пешеходов А. П. aka fresco (fresco_pap@mail.ru) at Дубейко Вячеслав : Vyacheslav Dubeyko's, reiser4_design.pdf , which --after perusing -- sparked my curiosity to search, find, and download, additional PDF archive from Как устроена файловая система reiser4, Журнале "Системный администратор", No 4 (апрель) 2006 г.
How the reiser4 file system works, "System administrator" Journal, № 4 (April) year 2006.1, 2, 3, 4, 5, 7 Main Contrasting differences in PDFs' content cited a priori.
6
creat()is referenced, as well, in
reiser4/plugin/plugin.h and reiser4/key.hPlease consult updated reiser4 information, code and/or comments, available by principal reiser4 developer, Mr. Edward Shishkin, at reiser4.wiki.kernel.org
P.S. The original image for the article was that of a wall but, given the historical fact that Russians are not fascists --since at least some 30 million of them died as they fought off western European fascism, especially during the 'Great Patriotic War'-- I assume its author desired to convey reiser4 hardened resiliency. Notwithstanding, I see walls associated with current Nazi regime at the White House who keeps children and destitute victims of past and present USA imperial aggression in 'Central and South America' jailed in concentration camps --all while shamelessly accusing others of 'human rights violations'; I associate walls with the Zionist regime who operates 'the largest open air prison in the world' --all while shamelessly playing the victim card.
In fact, walls are a feature of racists, genocidal land thieves, plunderers, and religious fanatics. Period.
Post may be altered as new technical information emerges and/or corrected translations and/or information becomes available. Accordingly, although I have made considerable efforts researching this article, the information contained here is available AS-IS and with no implicit nor explicit guarantee that it will be accurate or that it will perform adequately for group or individual(s) reading content derived from Metztli IT blog collections.